ChatGPT 对行业的影响
作者:小城 发布时间:2023-03-17
ChatGPT-4 来了
ChatGPT-3.5发布的热潮尚未退去,令人震撼的GPT-4就在日前推出了。然后,3月16日,百度也正式发布了大语言模型、生成式AI产品“文心一言”。
OpenAI老板Sam Altman直接开门见山地介绍说:这是我们迄今为止功能最强大的模型!
拍一张照片上传给GPT-4,它就可以立马生成网站的HTML代码!
在性能表现上,OpenAI直接甩出一句话:在各种专业和学术基准上和人类相当!
正如之前传言,GPT-4确实拥有多模态能力,可以接受图像输入并理解图像内容。并且可接受的文字输入长度也增加到3.2万个token(约2.4万单词)。
升级之后,GPT-4在各种职业和学术考试上表现和人类水平相当。它以高分通过各种标准化考试:SAT拿下700分,GRE几乎满分,逻辑能力吊打GPT-3.5。
人工智能历史
人工智能已成为新一代信息时代的核心技术,广泛应用于多个领域,为数字经济的发展和产业数字化转型提供了底层支撑,并在各种应用场景中发挥着至关重要的作用。其中,最常见的应用场景包括自然语言处理、计算机视觉、推荐系统、预测分析等。过去十年来,人工智能技术在持续提高和改进,并不断冲击着人类的认知。
2012年,在ImageNet图像识别挑战赛中,一种神经网络模型(AlexNet)首次展现了明显超越传统方法的能力。
2016年,AlphaGo在围棋这一当时人们认为其复杂性很难被人工智能系统模拟的中国围棋挑战赛中战胜了世界冠军。
2017年,Google的Ashish Vaswani等人提出了 Transformer 深度学习新模型架构,奠定了当前大模型领域主流的算法架构基础。
2018年,谷歌提出了大规模预训练语言模型 BERT,该模型是基于 Transformer 的双向预训练模型,其模型参数首次超过了3亿(BERT-Large约有3.4个参数);同年,OpenAI提出了生成式预训练 Transformer 模型——GPT,大大地推动了自然语言处理领域的发展。
2018年,人工智能团队OpenAI Five战胜了世界顶级的Dota 2人类队伍,人工智能在复杂任务领域树立了一个新的里程碑;此后在2018年底,Google DeepMind团队提出的AlphaFold以前所未有的准确度成功预测了人类蛋白质结构,突破了人们对人工智能在生物学领域的应用的想象。
2019年,一种人工智能系统AlphaStar在2019年击败了世界顶级的StarCraft II人类选手,为人工智能在复杂任务领域的未来发展提供了有力的证明和支持。
2020年,随着OpenAI GPT-3模型(模型参数约1750亿)的问世,在众多自然语言处理任务中,人工智能均表现出超过人类平均水平的能力。
2021年1月,Google Brain提出了Switch Transformer模型,以高达1.6万亿的参数量成为史上首个万亿级语言模型;同年12月,谷歌还提出了1.2亿参数的通用稀疏模型GLaM,在多个小样本学习任务的性能超过GPT-3。
2022年2月,人工智能生成内容(AIGC)技术被《MIT Technology Review》评选为2022年全球突破性技术之一。同年8月,Stability AI开源了文字转图像的Stable Diffusion模型。也是在8月,艺术家杰森·艾伦(Jason Allen)利用AI工具制作的绘画作品《太空歌剧院》(Théâtre D’opéra Spatial),荣获美国科罗拉多州艺术博览会艺术竞赛冠军,相关技术于年底入选全球知名期刊《Science》年度科技突破(Breakthrough of the Year 2022)第2名。
chatGPT 历史

2017年,谷歌大脑团队(Google Brain)在神经信息处理系统大会(NeurIPS,该会议为机器学习与人工智能领域的顶级学术会议)发表了一篇名为“Attention is all you need”(自我注意力是你所需要的全部)的论文[1]。作者在文中首次提出了基于自我注意力机制(self-attention)的变换器(transformer)模型,并首次将其用于理解人类的语言,即自然语言处理。
Transformer模型自诞生的那一刻起,就深刻地影响了接下来几年人工智能领域的发展轨迹。短短的几年里,该模型的影响已经遍布人工智能的各个领域——从各种各样的自然语言模型、到预测蛋白质结构的AlphaFold2模型,用的都是它。
2015年12月,OpenAI公司美国旧金山成立。特斯拉的创始人马斯克也是该公司创始人之一,为公司早期提供了资金支持(后来他从该公司退出,但保留了金主身份,并未撤资)。成立早期,OpenAI是一家非营利组织,以研发对人类社会有益、友好的人工智能技术为使命。2019年,OpenAI改变了其性质,宣布成为营利机构,这个改变与Transformer模型不无相关。
2018年,在Transformer模型诞生还不到一年的时候,OpenAI公司发表了论文“Improving Language Understanding by Generative Pre-training”(用创造型预训练提高模型的语言理解力),推出了具有1.17亿个参数的GPT-1(Generative Pre-training Transformers, 创造型预训练变换器)模型。这是一个用大量数据训练好的基于Transformer结构的模型。他们使用了经典的大型书籍文本数据集(BookCorpus)进行模型预训练。该数据集包含超过7000本从未出版的书,类型涵盖了冒险、奇幻、言情等类别。在预训练之后,作者针对四种不同的语言场景、使用不同的特定数据集对模型进行进一步的训练(又称为微调,fine-tuning)。最终训练所得的模型在问答、文本相似性评估、语义蕴含判定、以及文本分类这四种语言场景,都取得了比基础Transformer模型更优的结果,成为了新的业内第一。
2019年,该公司公布了一个具有15亿个参数的模型:GPT-2。该模型架构与GPT-1原理相同,主要区别是GPT-2的规模更大(10倍)。同时,他们发表了介绍这个模型的论文“Language Models are Unsupervised Multitask Learners” (语言模型是无监督的多任务学习者)[3]。在这项工作中,他们使用了自己收集的以网页文字信息为主的新的数据集。不出意料,GPT-2模型刷新了大型语言模型在多项语言场景的评分记录。在文中,他们提供了GPT-2模型回答新问题(模型训练数据中未出现过的问题及其答案)的结果。
2020年,这个创业团队再次战胜自己,发表论文“Language Models are Few-Shot Learner”(语言模型是小样本学习者)[4],并推出了最新的GPT-3模型——它有1750亿个参数。GPT-3模型架构与GPT-2没有本质区别,除了规模大了整整两个数量级以外。GPT-3的训练集也比前两款GPT模型要大得多:经过基础过滤的全网页爬虫数据集(4290亿个词符)、维基百科文章(30亿词符)、两个不同的书籍数据集(一共670亿词符)。
由于巨大的参数数目以及训练所需数据集规模,训练一个GPT-3模型保守估计需要五百万美元至两千万美元不等——如果用于训练的GPU越多,成本越高,时间越短;反之亦然。可以说,这个数量级的大型语言模型已经不是普通学者、一般个人能负担得起研究项目了。面对如此庞大的GPT-3模型,用户可以仅提供小样本的提示语、或者完全不提供提示而直接询问,就能获得符合要求的高质量答案。小样本提示是指用户在提问时先给模型提供几个例子,然后再提出自己的语言任务(翻译、创作文本、回答问题等)。
GPT-3模型面世时,未提供广泛的用户交互界面,并且要求用户提交申请、申请批准后才能注册,所以直接体验过GPT-3模型的人数并不多。根据体验过的人们在网上分享的体验,我们可以知道GPT-3可以根据简单的提示自动生成完整的、文从字顺的长文章,让人几乎不能相信这是机器的作品。GPT-3还会写程序代码、创作菜谱等几乎所有的文本创作类的任务。早期测试结束后,OpenAI公司对GPT-3模型进行了商业化:付费用户可以通过应用程序接口(API)连上GPT-3,使用该模型完成所需语言任务。2020年9月,微软公司获得了GPT-3模型的独占许可,意味着微软公司可以独家接触到GPT-3的源代码。该独占许可不影响付费用户通过API继续使用GPT-3模型。
2022年3月,OpenAI再次发表论文“Training language models to follow instructions with human feedback”(结合人类反馈信息来训练语言模型使其能理解指令),并推出了他们基于GPT-3模型并进行了进一步的微调的InstructGPT模型。InstructGPT的模型训练中加入了人类的评价和反馈数据,而不仅仅是事先准备好的数据集。
GPT-3公测期间用户提供了大量的对话和提示语数据,而OpenAI公司内部的数据标记团队也生成了不少人工标记数据集。这些标注过的数据(labelled data),可以帮助模型在直接学习数据的同时学习人类对这些数据的标记(例如某些句子、词组是不好的,应尽量少使用)。
OpenAI公司第一步先用这些数据对GPT-3用监督式训练(supervised learning)进行了微调。
在今年神经信息处理系统大会会议期间,OpenAI公司在社交网络上向世界宣布他们最新的大型语言预训练模型:ChatGPT。
与InstructGPT模型类似,ChatGPT是OpenAI对GPT-3模型(又称为GPT-3.5)微调后开发出来的对话机器人。OpenAI官网信息显示,ChatGPT模型与InstructGPT模型是姐妹模型。由于最大的InstructGPT模型的参数数目为1750亿(与GPT-3模型相同),所以有理由相信ChatGPT参数量也是在这个数量级。但是,根据文献,在对话任务上表现最优的InstructGPT模型的参数数目为15亿,所以ChatGPT的参数量也有可能相当。
自美国时间12月2日上线以来,ChatGPT已经拥有超过一百万的用户。用户们在社交媒体上晒出来的对话例子表明ChatGPT这款模型与GPT-3类似,能完成包括写代码,修bug(代码改错),翻译文献,写小说,写商业文案,创作菜谱,做作业,评价作业等一系列常见文字输出型任务。ChatGPT比GPT-3的更优秀的一点在于,前者在回答时更像是在与你对话,而后者更善于产出长文章,欠缺口语化的表达。有人利用ChatGPT与客服对话,要回了多交了的款项(这或许意味着ChatGPT在某种意义上通过了图灵测试),或许ChatGPT能成为社恐人士的好伙伴。
chatGPT进入公众视野后,我们可以看到他在社会面的一些应用进展,例如ChatGPT通过谷歌L3入职面试,获得年薪为18万美元的offer;ChatGPT碾压阿里二面面试官,并拿到offer;ChatGPT 参加美国医生执照的三项考试,考试成绩可以达到或接近及格通过水平;ChatGPT 在法律领域的表现甚至更加优秀,研究人员发现,ChatGPT 可以取得美国多州律师考试的及格分数;毫末智行准备将ChatGPT应用于自动驾驶;ChatGPT上线微软搜索引擎Bing,微软市值一夜飙涨5450亿;《时代》专访ChatGPT;89%的美国大学生用ChatGPT写作业,甚至拿下论文最高分;美团网创始人王慧文自掏5000万美元,下场组队研发ChatGPT;以色列总统使用ChatGPT写的演讲稿骗过现场2万听众等等。这说明了ChatGPT对于消费者来说是多么有趣和实用。
ChatGPT 团队
ChatGPT项目团队不足百人,其中有6人毕业于中国高校
近日,智谱研究联合 AMiner 发布的《ChatGPT 团队背景研究报告》显示,该团队规模不足百人,平均年龄为32岁,“90后”是主力军。团队中,共有9名华人,其中5人在中国内陆高校读完了本科。值得注意的是,团队并不一味强调高学历,其成员并非“清一色”的研究生学历,而是本、硕、博人数相对均衡。总体上看,OpenAI的显著特征是成员年纪很轻,华人员工抢眼;学历背景豪华,同时崇尚创业;业务聚焦技术,而且积累深厚。
根据OpenAI官网显示,这是一家致力于人工智能研究的非营利机构,团队规模仅87人。其中包含公司联合创始人Wojciech Zaremba在内,共有研发人员共77人,占比达到88%;另外还有4人产品人员,和6名其他岗位人员。团队中,华人员工共有9人。
在团队年龄构成上,20至29岁的成员有28人,占全体成员的34%;30至39岁的共50人,占61%;40至49岁的3人,无50至59岁年龄段的成员,60岁以上的有1人。经计算,该团队平均年龄为32岁。
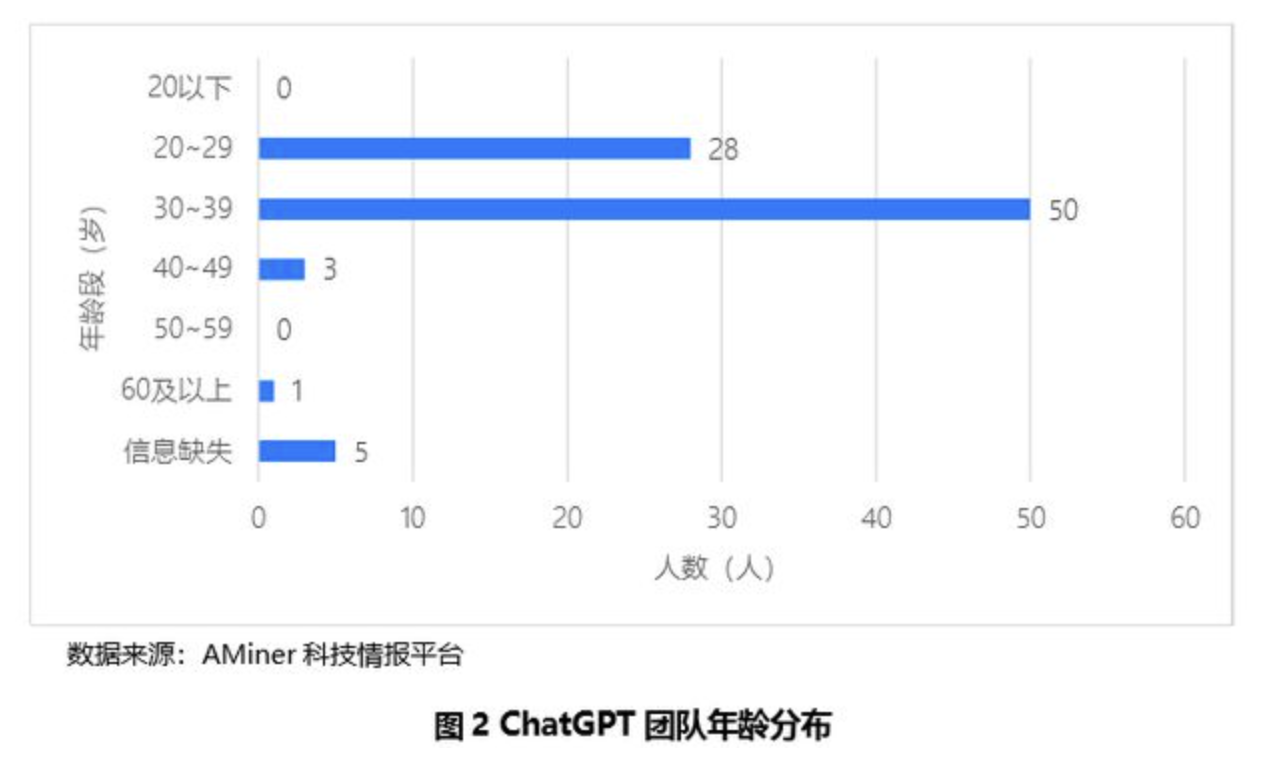
由此可见,“90后”是ChatGPT团队的主力军。这些在业内还经常被认为是研发经验不足的年轻人,事实上完全可以在前沿科技领域取得重大突破,并且引领了当前的大模型技术的创新风潮。
人工智能技术虽然专业性极强,但在ChatGPT团队并非“清一色”研究生学历,而是本、硕、博人数相对均衡。统计显示,团队中本科学历有27人,25人为硕士研究生学历,28 人拥有博士研究生学历,占比分别为33%、30%、37%。

从团队成员毕业高校分布看,斯坦福大学校友最多,共14人;其次是加州大学伯克利分校,共10人;第三是麻省理工学院,共7人;清华大学与卡内基梅隆大学并列第7名,各有3人。
值得注意的是,团队中有6人曾毕业于中国高校,其中5人本科就读于在中国内陆高校。他们中有3人本科毕业于清华大学,各有1人本科毕业于华中科技大学、北京大学/香港大学,1人硕士研究生毕业于台湾交通大学。他们在中国的顶尖高校本科毕业后就赴海外深造,获得硕士或博士学位,然后加入当地的创新型公司。
重要技术贡献者仅11人
ChatGPT是OpenAI在大型语言模型领域多年技术积累的结果。
报告显示,与ChatGPT相关的先前关键技术项目有RLHF(Reinforcement Learning from Human Feedbac,人类反馈强化学习)、GPT1、GPT2、 GPT3、CodeX、InstructGPT、webGPT等7项。
统计发现,ChatGPT项目的相对重要的贡献者有11人,其中有2人参与了其中4项关键技术项目的研发,另有9人参加了其中的3个关键技术项目研发。值得注意的是,华人欧阳龙是InstructGPT论文的第一作者,也是RLHF论文的第二作者,为这两个关键技术项目的核心人员。
在上述7大技术项目中,ChatGPT团队成员参与人数最多的是CodeX项目,共有22人,占总团队人员总数的25%;其次是webGPT和instructGPT,共有9人;第三是GPT3,共有6人。可见,ChatGPT团队成员在生成式预训练语音模型领域有较深厚的技术积累,四分之一的团队成员曾参与过同样基于GPT3的CodeX项目的研发经验,这为研发ChatGPT打下了坚实基础。
ChatGPT 会不会导致底层程序员失业?
一般有三种类型的人群,都各种有自己的看法,我们来看下各位大佬们都是怎么看待ChatGPT对未来程序员行业的影响与冲击的!最后一位就是chatGPT自己。
第一类:乐观派
乐观派认为ChatGPT不会导致底层程序员失业!
群友:我的答案是不会。因为ChatGPT是自然语言的处理工具,而并非编程AI,ChatGPT只是会一些编程,在目前ChatGPT写的代码还有比较明显的问题,且由于ChatGPT是语言AI,所以后续大概率不会向编写代码的方向去迭代,所以ChatGPT不会造成程序员失业。
群友:不会。程序员的核心不在于实现一个功能甚至不在于写出代码,而在于编码思维。编码思维这个东西包含了结构化思维、推演逻辑、算法、数学、架构、工作经验等等。是一个极其复杂的事物。ChatGPT的确可以给出特定问题的解法,但应用到具体的环境,具体的问题还是需要人去解决的。
群友:不管是之前就有的 Copilot 还是最近刚发布的 ChatGPT,其主要目的都是为提高生产效率。这里不存在导致“底层程序员失业”,如果对效率有大幅提升,但是市场又没有大幅增长的时候,可能会导致整体程序员的失业率上升,不会只是针对底层的。
第二类:悲观派
群友:我觉得不止是程序员,配合物联网和机器人,绝大多数工作都会被取代。再进一步想,99.99%的人类都会被取代。
群友:不止是程序员,以语言,逻辑,想象力和社会学为基础的职业都可能被取代,比如甚至律师。这玩意能给你起草法律文件。目前有些问题会给你报错,但你多调戏一会,换着方子问,它什么都会告诉你。
群友:反正我用google的频率已经大幅下跌,项目报告的矫正也全部都用它,它还能提供少量工程设计思路。再让它迭两代,google很有可能会遇到目前Meta的情况。不过已经有议员和律师提议禁止Chatgpt的使用了,因为会威胁到太多人。
第三类:中立派
以chatGPT自身为代表,看看它自己是如何回答的:
ChatGPT是一种基于自然语言生成的人工智能技术,它主要用于自动回复聊天内容。它的出现可能会对底层程序员造成一定的影响,但不会导致底层程序员失业。
首先,ChatGPT的出现会提高聊天应用的自动化水平,使其能够快速有效地回复用户的消息。这可能会对一些简单的聊天应用程序开发工作造成冲击,但并不会导致底层程序员失业
其次,ChatGPT本身也需要程序员进行开发和维护。它的出现可能会对一些人工智能程序员造成冲击,但也会为他们带来新的工作机会。
总的来说,ChatGPT的出现会提高聊天应用的自动化水平,但不会导致底层程序员失业。它的出现可能会带来新的工作机会,并对一些程序员造成冲击,但最终会有利于整个行业的发展。
你怎么看待ChatGPT对行业的影响呢?

智城外包云平台
智城外包网,连接企业软件开发需求与专业软件开发团队。帮助伙伴一起成长!
全流程在线操作,全流程在线工作,全流程在线保障
十年诚信运营,可信实名认证
微信公众号:智城外包网